AI Games
![]()
En un principio iba a hacer esto en inglés, pero me ha dado pereza y ya que no es una guia de uso ni nada pues lo hago en castellano y tirando.
En este artículo voy a ir poniendo distintos proyectos de redes neuronales y algoritmos de machine learning que hago para aprender y sobre todo porque estos proyectos me divierten muchísimo. No soy ninguna experta y voy aprendiendo sobre la marcha, así que es probable que estos proyectos estén repletos de errores, ya que no es nada importante y no los pulo al 100% por no perder mas tiempo de lo que me ha servido para aprender y divertirme un rato y así no quemarme.
UNO

Este proyecto lo hice después de terminar el del Tetris. La idea era hacer otro juego pero con un algoritmo evolutivo en vez de utilizar reinforcement learning. Y mediante la interfaz gráfica se puede entranar un nuevo modelo o cargar uno ya entrenado, y para entrenarlo de forma mas rápida está el otro script que esta optimizado y cada diez partidas guarda el modelo que va mejorando poquito a poquito (de esta forma se puede entrenar un modelo de forma más rápida).
Explicación visual: https://www.youtube.com/watch?v=9U37hSHYfXk
https://github.com/AirilMusic/AI/tree/main/unoAI
FUNCIONAMIENTO
La idea del funcionamiento se basa en que hay entre dos y diez jugadores, cada uno controlado por una red neuronal distinta. En la primera partida las redes son completamente aleatorias y luego la idea es que cuando un jugador se quede sin cartas ese jugador ha ganado, por lo que en muchos casos (no en todos porque puede haber tenido “suerte”) será la mejor red. Entonces esa red se copiará en todas las demás y una vez hecho eso, en el primer jugador se mantendrá igual pero en los otros tiene una probabilidad de que mute, es decir, que se le añadan capas, neuronas, se le cambien los pesos… Y así todo el rato para que si hay una mutación mejor el modelo mejore y si no la hay entonces la red original ganará (en la mayoria de casos) y se mantendrá igual hasta que haya una mutación mejor.
Decidí no complicarme con cosas como dropouts… ya que la idea era aprender sobre como hacer un algoritmo evolutivo, y tal y como funciona el juego es poco probable que se de overfiting, porque las cartas al repartirse son aleatorias y para este propósito añadí que el número de jugadores también fuese aleatorio.
Y a su vez añadí que al ejecutarse el programa con interfaz gráfica te de la opción de cargar un modelo previamente entrenado o entrenar uno desde cero. Y para entrenar modelos de forma más rápida y guardarlos hice un segundo script que es lo mismo pero sin interfaz gráfica y optimizado para que fuese un poquito más rápido y guardase el modelo cada diez partidas.
(Contexto: este proyecto lo empecé cuando me operaron, el carto día o así despues de la operción, y el tercero por la mañana me dieron morfina, así que os imaginareís como andaba de drogada XD)
PACKMAN (el señor de los packs, es bromi XD)
WORK IN PROGRESS
TETRIS

Este proyecto lo hice a finales de bachiller cuando despues de trastear con aprendizaje supervisado para hacer predicciones, luego redes convolucionales para clasificación de imagenes… Quise explorar el mundo del aprendizaje “autónomo” por así decirlo. Para iniciarme en este extenso mundo, empecé con el algoritmo que me pareció más simple (aunque ahora mismo los algoritmos evolutivos me parecen mas simples y faciles de implementar), aunque me supúso todo un reto al principio.
https://github.com/AirilMusic/AI/blob/main/tetris%20AI/tetris_for_AI.py
La razón por la que elegí el tetris es porque es muy fácil representar el tablero de jeugo en una matríz, y encima de forma binaria (las casillas ocupadas = 1 y las libres = 0), entonces la idea fue crear la matriz y que las piezas al colocarse se convirtiesen en 1. Y luego la pieza que se mueve con otro número, por ejemplo 2.
Entonces a la red hay que meterle los valores de esa matriz, cada neurona de entrada es una casilla y luego las neuronas de salida son 4 posibilidades (Abajo, Derecha, Izquierda, Rotar):
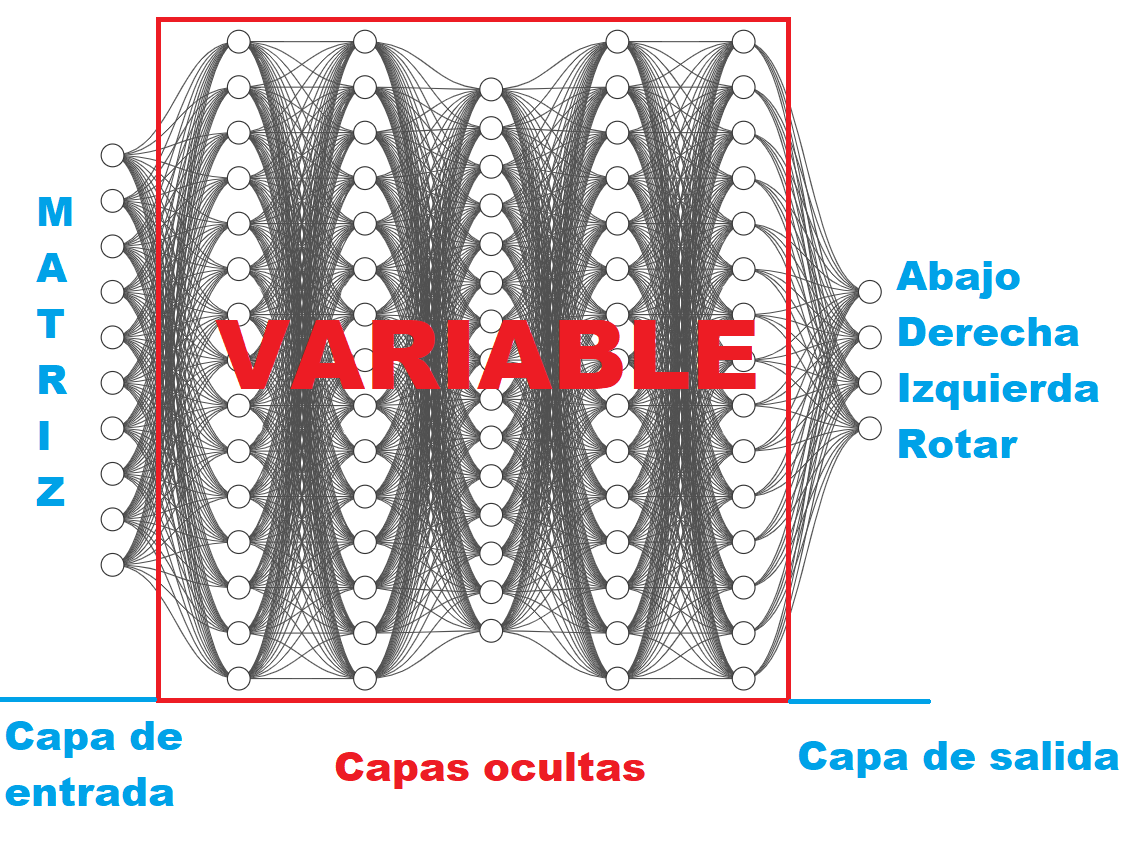
Entonces una vez tenemos la estructura inicial de la red, ahora tenemos que encontrar la estructura optima de las capas ocultas, los pesos y sesgos optimos… Por ejemplo en un modelo de aprendizaje supervisado básico podríamos ajustar las capas ocultas de forma manual, y en uno no tan básico también, pero ya que el modelo va a aprender por su cuenta de forma “autonoma” también podemos hacer que valla probando a ver cual es la estructura que mejor funciona.
Reinforcement learning
Hata ahora la creación de la red era como de normal, pero aquí es donde cambia para no necesitar datos de prueba ni datos etiquetados ni nada de eso. La idea es que le damos un escenario (el tablero) donde puede ejecutar acciones (Abajo, Derecha, Izquierda, Rotar) y que segun sus acciones pase una cosa u otra.
Claro, de primeras la red no tiene ninguna forma de mejora, porque no hay nada que pueda interpretar como positivo o negativo, solo ve que cambian cosas pero esos cambios no significan nada. Así que a las distintas cosas que pasen les tenemos que dar un valor:
Pieza colocada = +1
Línea destruida = +10
Muerte = -50
(Nota: si no pasa nada de eso la recompensa es 0, entonces tiene un enfoque a medio plazo ya que para recibir una recompensa tiene que llegar a colocar la pieza, ahora más adelante lo explico mejor)
Vale entonces ahora necesitamos un algoritmo que teniendo el entorno en forma de matriz, las acciones posibles y las recompensas (a cada acción realizada) eliga la mejor siguiente acción. Para esto hay varios algoritmos que podemos utilizar, uno de los más populares y el más adecuado en este caso es el Q-Learning:
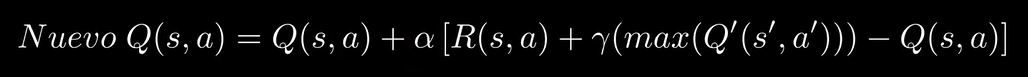
Nuevo Q(s,a) = nuevo valor de recompensa para el estado en el que nos encontremos y la acción que va a realizar
Q(s,a) = Valor actual de la acción que va a realizar en el estado actual
Alpha = la tasa de aprendizaje, cuanto menor sea mas precisa será la red, pero mas tiempo le tomará entrenarse lo suficiente (una forma de reducir el tiempo de entrenamiento, pero que lo aplicaré a partir de la red del Packman, es que al principio sea grande y se valla reduciendo a lo largo del entrenamiento)
R(s,a) = recompensa obtenida al hacer la última acción
Gamma = factor de descuento (entre 0 y 1), es decir, lo que hace que el modelo busque la recompensa a corto o largo plazo, cuanto menor sea, buscará a corto plazo, y cuanto mayor sea buscará a largo plazo.
max(Q'(s',a')) = valor máximo de cualquier acción del siguiente estado
Aunque para no complicarme, una vez compilado el modelo, utilicé la funcion q_learning_update() de tensorflow, para que cada vez que la red realiza una acción se reentrene teniendo en cuenta el resultado de esa acción.
Y de esta forma la red va optimizandose poquito a poquito jugando una y otra vez, para ganar la mayor cantidad de puntos posibles.
Para entenderlo mejor, voy a poner un ejemplo cute que se me acaba de ocurrir. Es como que tenemos un monstruito y queremos que aprenda a jugar, si coloca una pieza le damos una galletita, y el monstruito esta feliz, entonces intentará colocar piezas para que le demos galletitas. Pero por casualidad en un momento rellena una fila, y se rompe, y le damos diez galletitas, pues el monstruito estará muy muy feliz, pero en ese momento no sabrá porque, entonces cuando repita varias veces (por casualidad) lo de romper una linea, verá la correlación entre eso y la recompensa, así que aprenderá a romper lineas. Pero por el contrario, si el monstruito pierde, le hacemos bonk y lo castigamos, entonces el monstruito estará triste y aprenderá que tiene que evitar eso.
Nota: a corto plazo, como la acción mas probable que ocurra y de una recompensa es que coloque una pieza (+1) lo mas probable es que pase mucho tiempo al principio haciendo columnas de piezas y perdiendo en bastante poco tiempo (o rellenando el tablero pero dejando huecos), la cosa es esperar hasta que por casualidad encuentre que al romperse una linea le da puntos y eso pase varias veces hasta que se adapte para romper lineas en vez de colocar torres de piezas. Esto se puede mejorar modificando el valor gamma de la formula de q-learning.
(Contexto: esto lo estuve programando en segundo de bachiller en clase mientras los demas estaban super estresados con selectividad, y yo como ni me habia apuntado pues eso, aunque me pasé todo bachiller estudiando pentesting, programación y machine learning, así que era lo normal XD y lo mas gracioso es que saqué una media de 7,6 en todo bachiller sin esforzarme nada)
4 EN RALLA (AlphaFir)
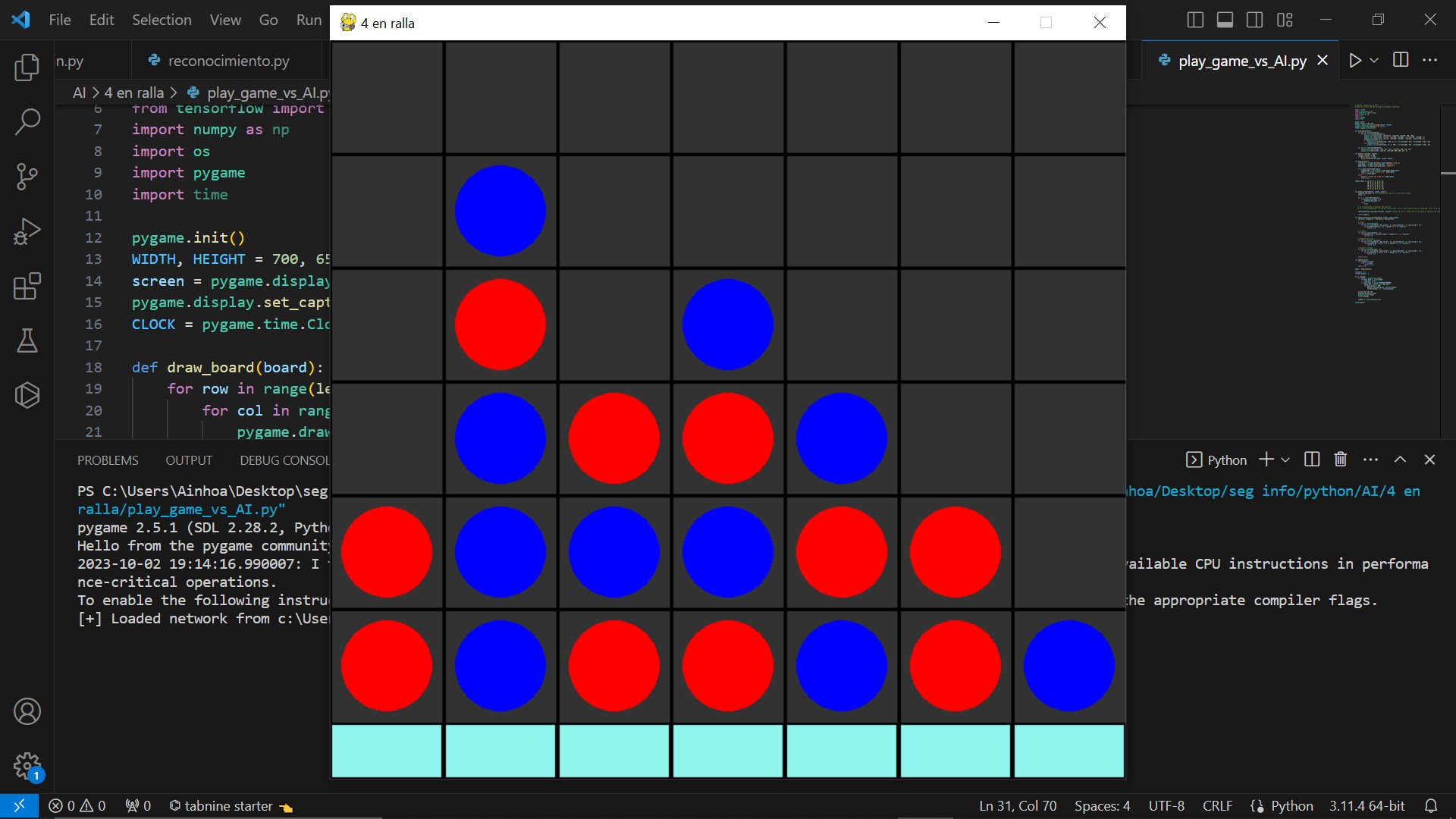
Este proyecto lo he hecho despues del UNO, para aprender sobre otras formas mas complejas de algorítmos de aprendizaje. Entonces para eso me puse a mirar distintos algoritmos de aprendizaje, y uno bastante interesante que encontré fué el de AlphaZero.
ENTRENAMIENTO
https://github.com/AirilMusic/AI/blob/main/4%20en%20ralla/model_trainer.py
El algoritmo de entrenamiento se basa en dos distintos algoritmos de Inteligencia Artificial, por un lado utiliza un arbol de busqueda de monte carlo (MCTS) y por el otro lado una red nueronal.
El Monte Carlo Tree Search es una variante de los arboles de búsqueda típicos, es decir, a partir de x posición que posibilidades hay, y a partir de cada posibilida que otras posibilidades habrá, y así todo el rato. Si el juego o las posibilidades son muy amplios, puede pasar que el arbol sea demasiado grande, por lo que para no recorrer todas las ramas y tardar demasiado tiempo se seleccionan aleatoriamente ramas y mediante estadistica se sacan probabilidades de que a partir de x acción puedan pasar otras cosas. Es decir, se hace un arbol de probabilidad pero eligiendo las ramas de forma aleatoria para no elegir todas, con lo que reducimos el número de operaciones para casos en los que el arbol sea demasiado grande.
Entonces Lo que hacemos es simular partidas y en cada posición de la partida utilizamos el MCTS para ver cual es el mejor movimiento, y creamos un dataset con los valores del estado del tablero y su correspondiente mejor movimiento.
Y una vez tenemos un dataset de bastantes partidas, lo que vamos a hacer es entrenar una red neuronal de forma “normal/básica”, es decir, Aprendizaje Supervisado.
Y este proceso lo vamos a repetir muchas veces, crear pequeños datasets e ir reentrenando el modelo para que valla mejorando poquito a poquito. El veneficio de esta técnica es que conseguimos una forma de predecir el mejor movimiento sin necesitan sin siquiera de hacer tantas operaciones como en el MCTS, simplemente entrenamos una red para que lo prediga.
JUEGO
Para el juego he representado la matriz con pygame, en cada partida el jugador que comienza el juego va cambiando, y un jugador es humano que interactua con el juego clicando en los botones de la parte inferior del tablero, mientras que el otro jugador es controlado por la red neuronal haciendo predicciones.
https://github.com/AirilMusic/AI/blob/main/4%20en%20ralla/game_vs_ai.py